中文句子拆分,音文对齐Stanza、Spacy、Jieba 、Aeneas 试用
小占时光 2025-07-23 13:38:30 6972
目录
背景
最近在搞一个文生视频的AI套壳项目,遇到一个问题就是,视频上需要显示字幕。如果直接按标点符号来分段,有一些比较长的,一屏幕就会显示不下,而且文本中有的符号是需要显示出来的,这就比较麻烦了,自己写的算法不一定能覆盖所有情况,就想着有没有工具可以来帮忙断句,所有就有了下面的这些项目测试。我的测试机器上安装有conda,如果步骤有差异的,可以自己补足。
Stanza
Stanza 是一个由斯坦福大学 NLP 实验室(Stanford NLP Group)开发的开源自然语言处理工具包。它是基于深度学习的,旨在为多种语言提供高效、精确的 NLP 任务处理。这个工具包特别适用于句法分析、词性标注、命名实体识别、依存句法分析等任务。 项目地址:https://github.com/stanfordnlp/stanza 中文模型地址:https://huggingface.co/stanfordnlp/stanza-zh-hans 下面直接开始测试效果如何。
pip install stanza
pip install torch numpy
安装完成后,(输入python后)直接运行代码
import stanza
# 下载并加载中文模型
stanza.download('zh')
nlp = stanza.Pipeline('zh')
# 测试输入文本
long_sentence = "示例文本"
doc = nlp(long_sentence)
for sentence in doc.sentences:
print(sentence.text)
很多人电脑不能访问外网,所以在模型下载哪一步就不不能继续了。如果有办法的可以到前面的模型地址下载,没法的就到下面百度网盘下载: https://pan.baidu.com/s/1iwfhx8x1d3D7NgGbfPpuyA?pwd=yrjr 下载后将代码改成:
import stanza
# 加载本地模型
model_path = 'D:/xxx/xxx/stanza-zh'
nlp = stanza.Pipeline('zh', package='default', dir=model_path, download_method=None)
# 处理输入文本
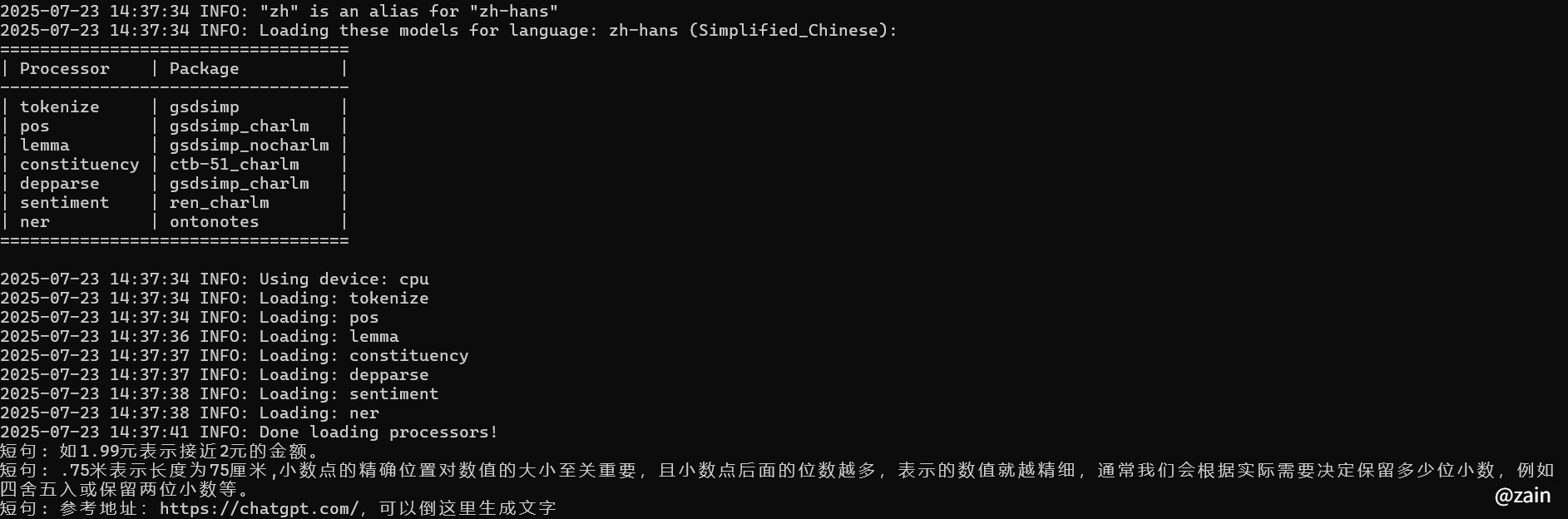
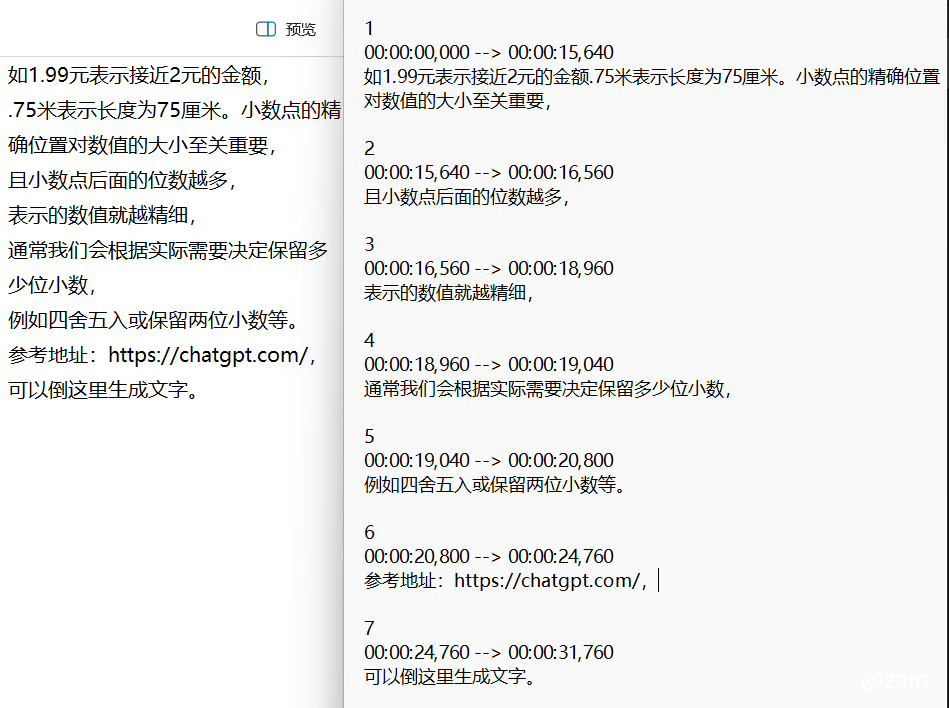
long_sentence = "如1.99元表示接近2元的金额。.75米表示长度为75厘米,小数点的精确位置对数值的大小至关重要,且小数点后面的位数越多,表示的数值就越精细,通常我们会根据实际需要决定保留多少位小数,例如四舍五入或保留两位小数等。参考地址:https://chatgpt.com/,可以倒这里生成文字"
# 进行句子拆分
doc = nlp(long_sentence)
# 输出拆分后的句子
for sentence in doc.sentences:
print(f"短句: {sentence.text}")
结果预览
Spacy
spaCy 是一个用于自然语言处理(NLP)的开源库,专注于高效、可扩展、易于使用的工具。它是由 Explosion AI 开发的,并且广泛应用于学术界、行业及个人项目中。spaCy 提供了丰富的工具和模型,能够帮助用户进行文本分析、信息提取、情感分析等任务。 首先,安装 spaCy 并下载一个预训练模型:
# 安装 spaCy
pip install spacy
# 下载英文预训练模型
python -m spacy download en_core_web_sm
运行代码
import spacy
# 加载中文模型
nlp = spacy.load("zh_core_web_sm")
# 创建中文文本
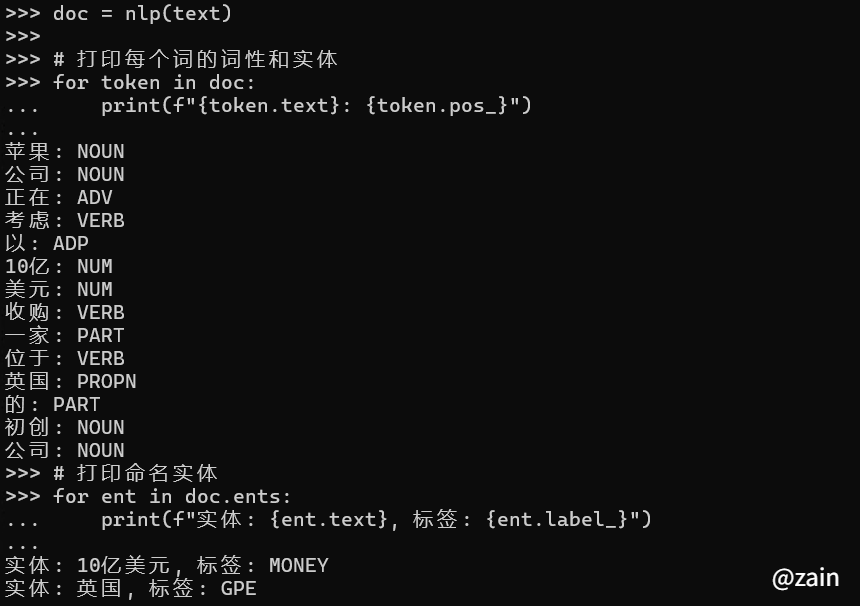
text = "苹果公司正在考虑以10亿美元收购一家位于英国的初创公司"
# 处理文本
doc = nlp(text)
# 打印每个词的词性和实体
for token in doc:
print(f"{token.text}: {token.pos_}")
# 打印命名实体
for ent in doc.ents:
print(f"实体: {ent.text}, 标签: {ent.label_}")
结果预览
import spacy
# 加载 Spacy 中文模型
nlp = spacy.load("zh_core_web_sm")
# 创建长文本
text = """
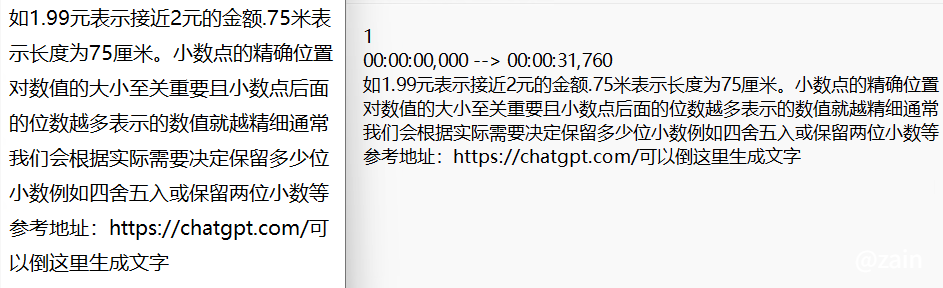
如1.99元表示接近2元的金额,.75米表示长度为75厘米。小数点的精确位置对数值的大小至关重要,且小数点后面的位数越多,表示的数值就越精细,通常我们会根据实际需要决定保留多少位小数,例如四舍五入或保留两位小数等。参考地址:https://chatgpt.com/,可以倒这里生成文字。
"""
# 使用 Spacy 处理文本
doc = nlp(text)
# 通过迭代器访问句子
for sent in doc.sents:
print(f"短句: { sent.text }")
结果预览

Jieba
Jieba 是一个常用的中文分词工具,它的主要功能是将一段中文文本拆分成一个个的词语。Jieba 分词是基于 Trie 树 和 前缀词典 实现的,并且支持 自定义词典,能够很好的处理中文文本中的各种情况。这个是国内的,但不符合需求,就简单介绍一下。
pip install jieba
运行代码
import jieba
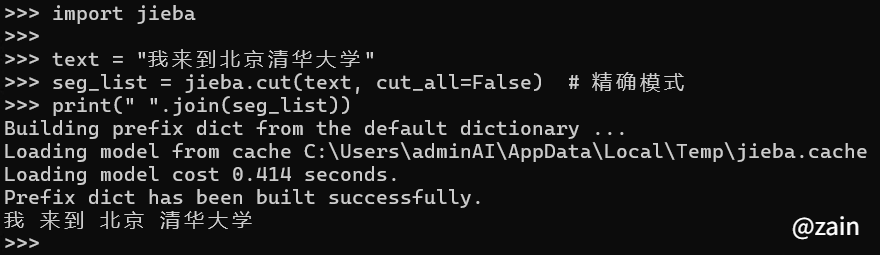
text = "我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=False) # 精确模式
print(" ".join(seg_list))
结果预览
Aeneas
这个应该是一个工具,我在B站上看到的,视频地址:https://www.bilibili.com/video/BV12m411Z77M?vd_source=bb826771ee43090917d63698c6fa129a&spm_id_from=333.788.videopod.sections。
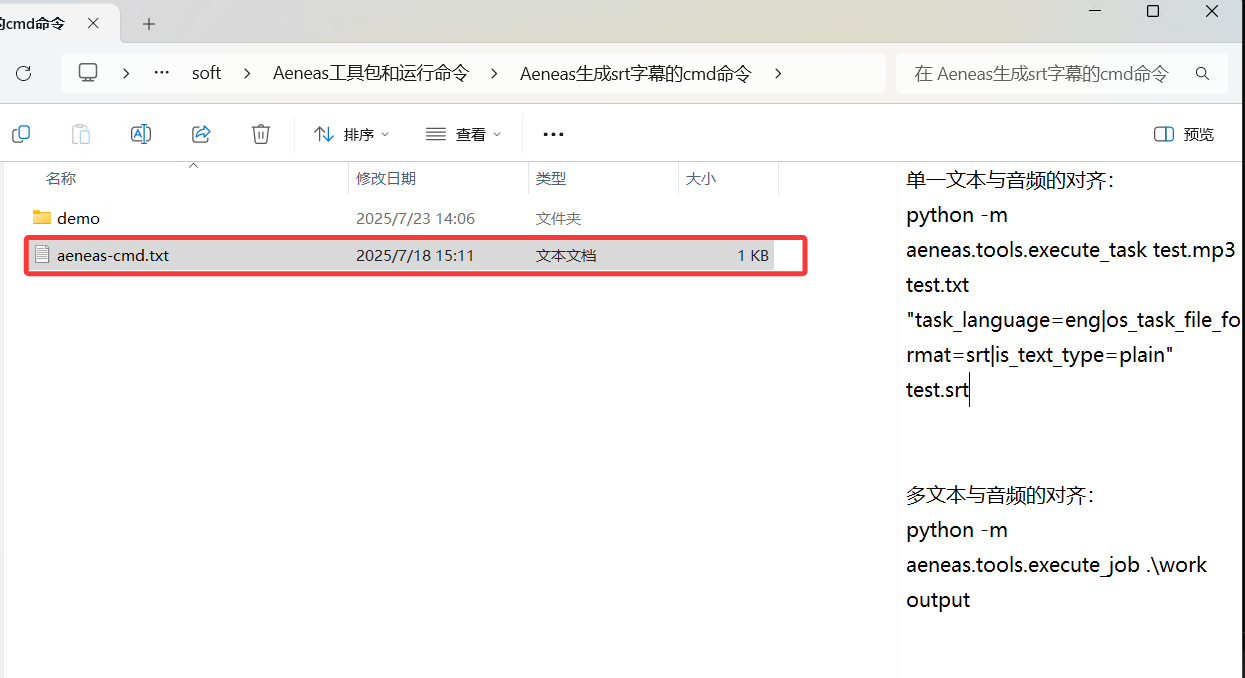
需要下载文件,作者给了一个百度网盘的地址,下载可用。下载好后,使用也比较简单。在安装好python 环境的机器上,打开软件目录,找到“aeneas-cmd.txt”,里面有执行的命令。


一堆的折腾也没有找出好用的,如果使用标点符号分割,那我直接手搓算法,自己判断了,不用大模型了。 余下还有一些没有测试过的,模型太大下不下来,如果真的有需要的也可以看看。
https://github.com/FreedomIntelligence/Soundwave?tab=readme-ov-file https://github.com/open-speech/speech-aligner
其实如果是自己用,那么自己打标点符号也行,可是用户就不好说了,可能会有长句,也可能在句子中会出很多特殊符号等。就希望人工智能能帮助智能处理掉,不管是音文对齐还是句子分割都好,如果有好用,且不用自己用手的,也希望大佬可以介绍。
最后一次修改 : 2026/8/3 上午6:02:33

